
はじめに
前編では、原稿を分解して整える部分を解説しました。後編では、整った原稿をWordPressに送り込み、壊れず再実行できる状態にする部分を扱います。
このフェーズで一番大事なのは、エラーから安全に戻れる設計です。投稿の途中で失敗したとき、半分だけ反映された状態が残ると復旧が困難になります。後編の設計は、ほぼ全部この一点に向けて組まれています。
後編の処理フロー

ポイントは、新規投稿と更新を同じスクリプトで扱うことです。最初は新規投稿用とリビジョン更新用のスクリプトを別ファイルにしていましたが、運用するうちに「ある記事を新規か更新か事前に意識する」のが面倒になり、統合しました。
1. Rinkerショートコード展開
YAMLフロントマターには、その記事で紹介する商材のIDが配列で書かれています。本文中の特定マーカー(<!-- rinker:001 -->のようなコメント)を、対応するRinkerショートコードに置換します。
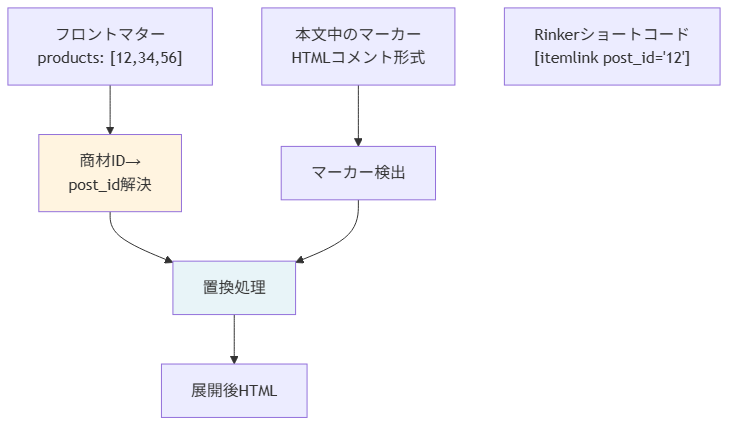
ここで決めた判断は、Rinker商材IDを原稿のフロントマターで「宣言」しておくことです。本文中にいきなりpost_idが出てくると、後から原稿を見直したときに「この記事で何の商品を紹介しているか」が把握しづらくなります。フロントマターに集約することで、メタデータと本文の役割分離が崩れません。
商材IDからRinkerのpost_idへの解決は、外部のキャッシュテーブル(SQLite)に保持しています。Rinker側のpost_idは私のWordPress内部のIDなので、原稿には書きません。原稿は「読者から見える商材ID」だけを持ち、内部IDは変換時に解決します。
2. 既存記事の検出と冪等性確保
スクリプトを再実行しても壊れないことを「冪等」と呼びます。冪等性は、自動化ツールが本番運用に耐える条件です。
冪等性を担保するために、投稿前に同じスラッグの記事が既にWPに存在するかを確認します。
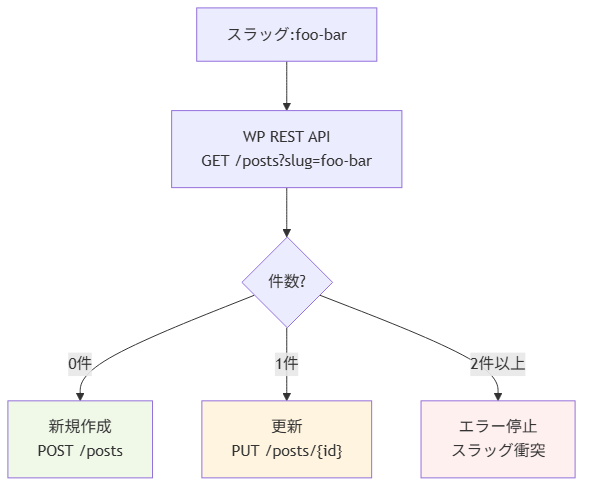
スラッグ衝突(2件以上)は理論上起こりませんが、過去に手作業で記事を複製したときに発生したことがあります。だからこそ、想定外の状況をエラーで止めるパスを明示的に置いています。
更新時は、既存記事のすべてのフィールドを上書きするのではなく、フロントマターで管理しているフィールドだけを送る設計にしています。WP管理画面で後から手動編集された項目(たとえばPV分析タグや手動で追加した内部リンク)を、自動投稿で消さないためです。
3. WP REST APIへの投稿
WordPress REST APIの呼び出しは、requestsライブラリで素直に行います。認証はアプリケーションパスワード方式で、Basic認証ヘッダに乗せます。
import requests
from requests.auth import HTTPBasicAuth
auth = HTTPBasicAuth(WP_USER, WP_APP_PASSWORD)
res = requests.post(
f"{WP_BASE}/wp-json/wp/v2/posts",
json=payload,
auth=auth,
timeout=30
)
res.raise_for_status()
ここで効くのが、raise_for_status()の徹底です。HTTPステータスが2xx以外なら必ず例外を出させることで、エラー時にスクリプトが先に進まないように担保します。
タイムアウトも必ず指定します。設定しないと、ネットワーク不調時にプロセスが永久に止まります。30秒で切って、その内訳を上位のリトライロジックに委ねます。
4. エラー処理の階層
エラーは発生箇所によって対応が違います。三層に分けて扱います。
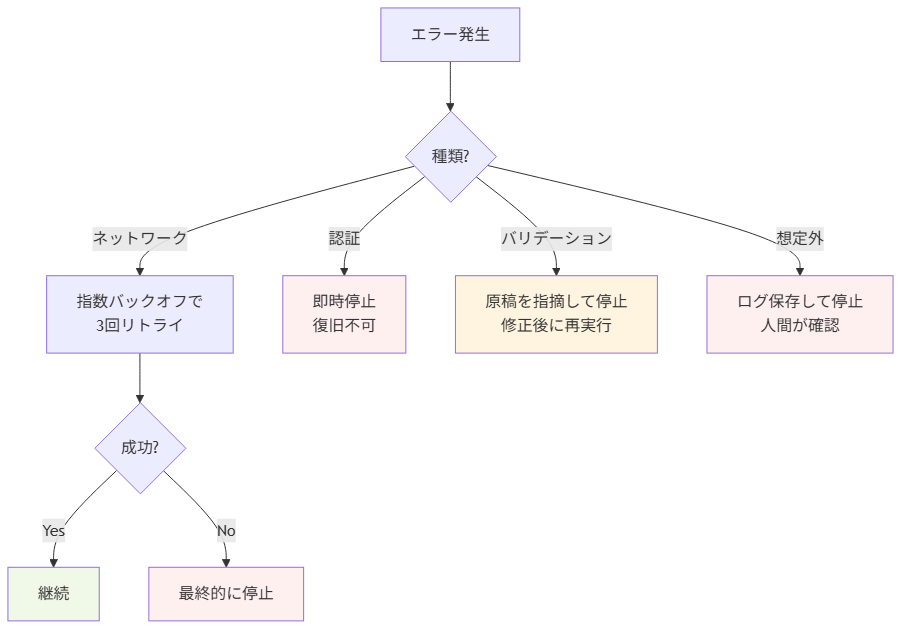
ネットワークエラーは時間が解決することがあるので、指数バックオフ(1秒、2秒、4秒)で三回までリトライします。それでも駄目なら停止。
認証エラーはリトライしても直りません。即停止して、設定ファイルを確認する旨をログに出します。
バリデーションエラーは原稿の問題です。何が問題か(必須項目の欠落、画像のalt未設定、JSON-LD不整合など)を具体的に出力し、原稿の修正を促して停止します。
想定外のエラーはとにかく止めます。半端な状態でリトライするより、人間が状況を確認する方が安全です。
「止まる方が、進むより安全」が、エラー処理全体の方針です。
5. 事後検証
投稿が成功しても、それで終わりではありません。投稿結果が期待通りに反映されたかを確認します。

事後検証は「失敗した場合のリトライ」ではなく、「気付かない劣化を検出する」役割です。WP側のキャッシュが効いて反映が遅れたり、画像のURL書き換えが完全には終わっていない、というケースを後から検出するためのものです。
設計時に却下した代替案
案:WordPress XML-RPC経由で投稿
XML-RPCはWordPressの旧来からの投稿APIで、Pythonライブラリも豊富にあります。
却下した理由は、REST APIで全て足りることと、セキュリティ的にXML-RPCを無効化するのが推奨という流れがあるためです。REST API中心に統一しておけば、XML-RPCを無効化したまま運用できます。
案:投稿ライブラリ(python-wordpress-xmlrpc等)を使う
既存ライブラリで投稿処理を抽象化する案も検討しました。
却下した理由は、自前で書いた方がデバッグしやすいためです。投稿時のエラーは原稿側に原因があることが多く、ライブラリ越しに調べるよりも、生のリクエスト・レスポンスをログに残せる素のrequestsの方が、私の運用には合っていました。
ここまでで自動投稿の骨格は完成
第1回から第4回までで、原稿フォーマット、CLAUDE.mdの三層構造、変換と投稿のスクリプトを揃えました。ここからは応用編に入ります。
次回予告
次回は Rinker連携の実装 を扱います。標準のRinkerプラグインの限界、functions.phpを拡張して独自エンドポイントを追加した理由、認証とセキュリティの設計、商材データを記事へ注入する一連の流れを解説します。アフィリエイト収益と自動化を両立させる、シリーズ中で最も技術寄りの回になります。
このシリーズで紹介する設計は、執筆時点の各ツールバージョンに基づきます。Claude Code、MCP、WordPress、各種APIは仕様変動が大きいため、最新ドキュメントとの照合をおすすめします。








