
はじめに
一年間ブログを自動化して、最も価値があったのはコードではなく、書かなかったコードの方だった。
このシリーズは、個人ブログをClaude Code前提で再設計した記録です。WordPress、Python、MCP、構造化データを組み合わせて、原稿から公開までを一本の流れに整えました。
最初に断っておくと、このシリーズで紹介するのは「コピーすれば動く完成品」ではありません。各人の環境・ジャンル・規模に依存する部分が多すぎて、汎用ツールとして提供する意味が薄いからです。
代わりに扱うのは、その手前の設計判断です。何を自動化して、何を自動化しなかったか。なぜそう決めたか。同じような自動化を考えている人が、自分の環境に当てはめて判断するための材料を残すことを目的とします。
英語圏ではこのテーマの記事がここ半年で急速に増えてきました。一方、日本語で体系的に設計判断を解説する記事はまだ少ないのが実情です。海外事例を眺めつつ、自分の環境に合わせて取捨選択するための、日本語の参照点を目指します。
自動化の目的は生産性ではなく一貫性
ブログ自動化の話は、たいてい「執筆が速くなる」「公開が楽になる」という生産性の文脈で語られます。間違ってはいませんが、本質ではないと考えています。
一人運営のブログで実際に起きる問題は、生産性より一貫性の欠如です。
- ジャンルごとに記事構造がバラバラになる
- 過去記事と新記事で文体が揺れる
- 日本語版と英語版でメタデータがズレる
- カテゴリ・タグの粒度が時期によって変わる
- 構造化データの実装が記事ごとに違う
これらは手作業で書き続けると必ず発生します。一年経つと、自分のブログを自分で検索しても見つからないという事態になります。
自動化の本当の目的は、こうした揺れを設計レベルで吸収することです。執筆速度はその副産物にすぎません。
システム全体像
全体は4つのレイヤーに分かれます。
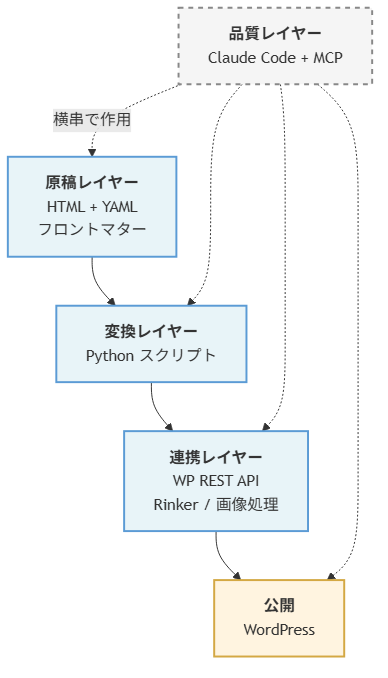
データは上から下へ流れますが、品質レイヤーだけは全体に横串で作用します。文体チェック、構造化データ検証、内部リンク提案などは、どのレイヤーでも呼び出します。
レイヤーを分けた理由は、変更の影響範囲を限定するためです。WordPressのテーマを変えても変換レイヤーは触らなくて済む。新しいアフィリエイトサービスを足しても原稿レイヤーは無傷でいられる。この独立性を最初に設計しておかないと、後から差し替えるコストが跳ね上がります。
4レイヤーの責務分離
原稿レイヤー:HTML + YAMLフロントマター
原稿はMarkdownではなくHTML + YAMLで書いています。理由は次回詳述しますが、要点は「最終出力に近い形式で書く方が、構造化データやレイアウト指定が直接埋め込める」という判断です。
YAMLフロントマターには次を入れます。
- タイトル、スラッグ、抜粋
- カテゴリ、タグ
- 公開日、更新日
- 構造化データの種別(Article / FAQPage / HowTo)
- 多言語版へのリンク(hreflang用)
- アフィリエイト商材のID配列
このレイヤーは「人間が書く領域」と「機械が読む領域」を分離する場です。後段のレイヤーは、フロントマターを読めば必要な情報がすべて揃うように設計しています。
変換レイヤー:Pythonスクリプト
変換レイヤーは、原稿を受け取って各APIに渡す形式に整えるだけの薄い層です。ビジネスロジックは入れません。
- HTMLとYAMLを分解する
- 画像参照をCDNパスに置き換える
- 構造化データのJSON-LDを生成する
- Rinker商材IDを実際のショートコードに展開する
- WP REST APIに投稿リクエストを送る
このレイヤーを薄く保つのは意図的です。変換ロジックが太ると、デバッグ時にどこで問題が起きたか追跡できなくなります。やることが少ないほど壊れにくい、という原則を採用しました。
連携レイヤー:外部API群
連携先は3種類です。
- WordPress REST API(記事本体、メディア、カテゴリ)
- Rinker(アフィリエイト商材データ、独自エンドポイント経由)
- 画像処理(WebP変換、alt自動付与)
ここで重要なのは、連携先ごとに独立した関数として分けることです。Rinkerが将来終了した場合、その関数だけ差し替えれば済むようにしておきます。
品質レイヤー:Claude Code + MCP
品質レイヤーは、他のレイヤーと違って「実行時に必ず通る」ものではありません。原稿執筆中・公開前・公開後のそれぞれで、必要に応じて呼び出します。
- 文体チェック(過去記事との一貫性)
- 構造化データの妥当性検証
- 内部リンク候補の提案
- タイトルとメタディスクリプションの整合確認
Claude Codeで対話的に動かす部分と、MCPで関数として呼ぶ部分を分けています。判断が要る作業は対話、定型処理はMCP、という切り分けです。
設計時に却下した代替案
ここが今回の本題です。選ばなかった理由の方が、選んだ理由より参考になります。
案1:Markdown + 静的サイトジェネレーター(Hugo / Astro / Next.js)
最初に検討したのはこの構成でした。GitHubで原稿管理、ビルドして静的サイトとして配信する流れです。
却下した理由は3つ。
- WordPressエコシステムを捨てるコストが大きい:アフィリエイトプラグイン、SEOプラグイン、コメント機能、すべて自前で再構築する必要がある
- AdSenseとの相性:静的サイトでもAdSenseは使えるが、収益最適化のためのプラグイン群が使えない
- 記事数が多い既存サイトの移行コスト:数百本規模の記事を移すスクリプトを書く工数が、得られるメリットを上回る
新規ブログを今から立ち上げるならAstro + microCMSなどは有力ですが、既存資産がある場合はWordPress継続が現実的でした。
案2:Headless CMS(microCMS / Contentful)+ WordPress表示
Headless CMSで原稿管理、WordPressは表示のみに使う構成も検討しました。
却下した理由は、プレビュー機能の弱さです。Headless構成だと、最終的なWordPressのテーマ適用後の見た目を執筆中に確認できない。スマホ表示でレイアウトが崩れるアフィリエイトボックスを、毎回プレビューサイトで確認する手間が許容できませんでした。
もう一つはコスト。月数千円の固定費を払い続けるなら、自前のPythonスクリプトでGit管理する方がランニングコストがゼロに近い。
案3:Notion + 自動公開ツール
Notionで原稿を書いて、自動でWordPressに送る構成も人気があります。
却下した理由は、Notionの構造表現力の限界です。JSON-LD構造化データ、hreflang、カスタムショートコードを記事ごとに細かく指定する手段がない。書きやすさは抜群ですが、最終出力の制御権を渡しすぎる感覚がありました。
ただしこれは個人の優先順位次第です。SEOや構造化データに強いこだわりがない場合、Notion運用は十分合理的な選択肢になります。
案4:WordPress標準のブロックエディタで完結
最も「素直」な選択肢です。プラグインで補強すればここまでの自動化は不要でした。
却下した理由は、バージョン管理の不在です。記事をGitで管理できないと、過去の編集履歴を辿れない、複数記事を一括で書き換えられない、Claude Codeから直接編集できない。原稿をテキストファイルとして所有することが、AI連携の前提になります。
このシリーズで扱う範囲と扱わない範囲
扱うこと:
- 各レイヤーの実装判断(CLAUDE.md構造、HTML+YAML設計、wp_import、Rinker連携、画像処理、運用)
- 設計時に却下した代替案
- 運用一年で見つかった事故と対応
扱わないこと:
- AI記事生成のプロンプティング技法(別シリーズで予定)
- SEO戦略全般(必要箇所のみ言及)
- 収益化施策の具体(自動化と直接関係する部分のみ)
- 特定プラグインのインストール手順(公式ドキュメント参照)
次回予告
次回は CLAUDE.md三層構造の設計判断 を扱います。グローバル・プロジェクト・タスクの3階層で責務を分けた理由と、各階層に何を書くかの線引きを解説します。
このシリーズで紹介する設計は、執筆時点の各ツールバージョンに基づきます。Claude Code、MCP、WordPress、各種APIは仕様変動が大きいため、最新ドキュメントとの照合をおすすめします。








