
2026年5月19日、PaaS(アプリケーションの実行環境を丸ごと提供するクラウドサービス)大手のRailwayが約8時間の全面障害を起こした。原因はソフトウェアのバグでも攻撃でもない。Google Cloud(GCP)の自動システムが、Railwayの本番アカウントを誤って停止したのである[1][2]。
Railwayは月額約200万ドルをGCPに支払う大口顧客であり、停止は同社の行為に起因しない一方的な措置だった[3]。さらに同社はGCP・AWS・自社ベアメタル(Railway Metal)にまたがるマルチプロバイダー構成を採っていたにもかかわらず、全ワークロードが停止した。冗長化の単位を「リージョン」までしか考えていない設計では、この障害は防げない。
本稿ではRailwayの公式インシデントレポート[1]をもとに、アカウントそのものが単一障害点(SPOF)になる構図と、マルチクラウドでも残る「コントロールプレーンの隠れ依存」を整理する。クラウドに本番を置くすべての組織にとって、依存の棚卸しを見直す材料になるはずだ。
何が起きたか:誤停止から8時間の全面障害へ
5月19日22時20分(UTC)、GCPの自動システムが複数アカウントを対象とする一括措置の一環として、Railwayの本番アカウントを事前通知なしに停止した[1][2]。ダッシュボードとAPIは即座に503エラーを返し、利用者はログインすらできなくなった。
Railwayの対応は速かった。22時10分の監視アラートから9分で根本原因を特定し、22時22分にGoogleへ緊急チケットを発行、22時29分にはアカウントへのアクセスが回復している[1]。それでも全面復旧は翌20日朝までかかった。
| 時刻(UTC) | 出来事 |
|---|---|
| 5/19 22:10 | 監視がAPIヘルスチェック失敗を検知 |
| 5/19 22:20 | GCPがRailway本番アカウントを誤停止 |
| 5/19 22:29 | エスカレーションによりアカウント回復 |
| 5/20 01:30 | 計算リソースの復旧開始、01:38にエッジ通信再開 |
| 5/20 02:55 | ダッシュボード回復 |
| 5/20 06:14 | 主要機能の復旧完了、監視フェーズへ |
アカウント自体は9分ほどで戻ったのに、復旧に8時間を要した点が本質である。停止されたVMの再起動、制御系の再構築、ルーティング情報の再配布という後始末は、停止の取り消しでは終わらない。
マルチクラウドでも全滅した理由:コントロールプレーンの隠れ依存
Railwayのワークロードは3つの基盤に分散していた。GCP停止の直後、AWSとRailway Metal上のワークロードは動き続けていた。エッジプロキシがルーティングテーブルのキャッシュを保持していたからである[1][2]。
しかしルート情報を配るネットワークコントロールプレーン(経路や構成を決める制御系)はGCP上にあった。キャッシュの有効期限が切れると、エッジは稼働中のインスタンスへの経路を解決できなくなり、AWSやベアメタル上のワークロードまで404を返し始めた[1]。データプレーン(実際の通信や処理を担う層)を分散しても、制御系が一点に集まっていれば、その一点が全体を道連れにする。
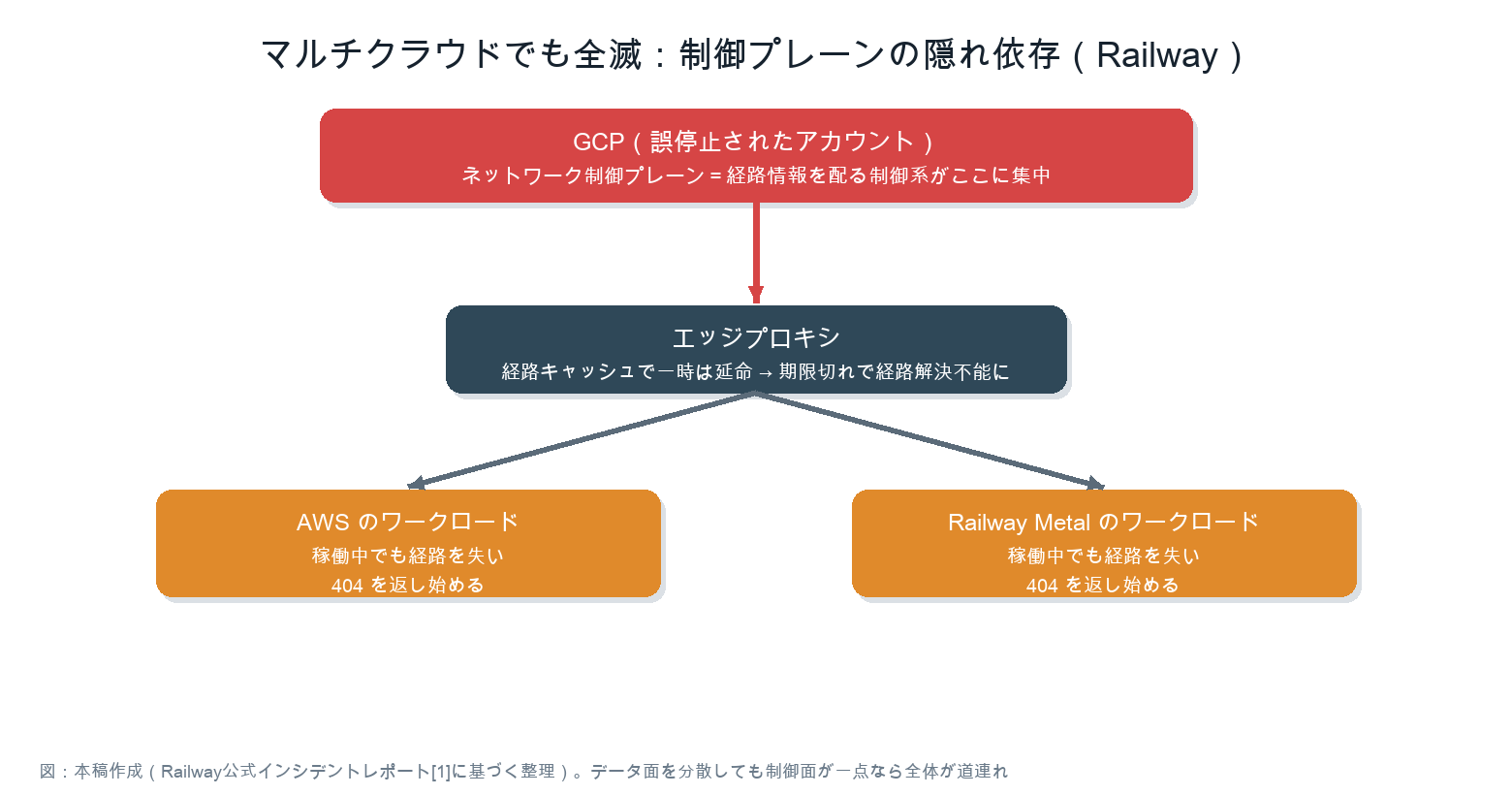
これはRailway固有の失敗ではない。認証基盤、シークレット管理、サービスディスカバリ、CI/CD、DNSなど、制御系に相当するコンポーネントが特定のクラウドの特定アカウントに集中している構成は珍しくない。構成図でデータの流れだけを見ていると、この依存は見えない。
アカウントは契約上のSPOFである
技術的な冗長化をどれだけ積んでも、アカウント停止はその全てを一括で無効化する。リージョン分散もマルチAZも、同一アカウント内にある限り運命を共にする。今回の措置は誤りだったが、決済トラブル、不正検知の誤判定、規約解釈の変更など、アカウント停止に至る経路は複数ある。
打てる手は段階的に考えるのが現実的だ。
| 対策 | 守備範囲 | コスト感 |
|---|---|---|
| 別アカウントへのバックアップ退避 | データの生存 | 小 |
| 制御系(DNS・認証・監視)の別事業者分離 | 復旧手段の確保 | 中 |
| データプレーンの複数事業者化 | 継続稼働 | 大 |
少なくとも監視とステータスページは、本番と同じアカウント・同じ事業者に置くべきではない。Railway自身も再発防止策として、GCPをデータプレーンの主経路から外し、ユーザー向けの中核サービスを特定ベンダーに依存させない構成への移行を表明した[1]。
技術面と並行して、契約面の備えも効く。Railwayの復旧が速かったのは、緊急チケットとアカウント担当者への直接エスカレーションという経路を即座に使えたからである[1]。自社の契約しているサポートプランで誰に・どの窓口で・何分以内に到達できるかは、障害当日ではなく今日確認できる項目だ。請求や本人確認の不備はアカウント停止の典型的な引き金になるため、支払い手段の冗長化と連絡先の最新化も地味だが効果がある。
経営層との対話では、これは技術論ではなく取引先リスクとして説明できる。単一仕入先に全生産を依存する製造業がないのと同じ理屈であり、クラウドアカウントは技術資産であると同時に、一方的に解約されうる契約でもある。
まとめ
Railwayの障害が示したのは、可用性設計の単位を「リージョン」で止めてはならず、「アカウント」「事業者」まで広げる必要があるという教訓である。そしてマルチクラウドを名乗る構成でも、コントロールプレーンの置き場所が一点なら、実態は単一依存と変わらない。
まず自社環境で、止まると全体が止まる制御系コンポーネントがどのアカウントにあるかを洗い出してほしい。次に、クラウドアカウントが明日停止された場合の復旧手順が存在するかを確認する。8時間で済んだRailwayは、対応が速かった部類なのだ。
出典
[1] Railway: Incident Report: May 19, 2026 – GCP Account Suspension — https://blog.railway.com/p/incident-report-may-19-2026-gcp-account-outage[2] InfoQ: Google Cloud Suspends Railway’s Production Account, Causing Eight-Hour Platform-Wide Outage — https://www.infoq.com/news/2026/05/railway-gcp-account-outage/
[3] The Stack: Google Cloud goes rogue again, cuts off $2m/month customer without warning — https://www.thestack.technology/google-cloud-goes-rogue-again-cuts-off-2m-month-customer-without-warning/








