
2026年5月7日、米暗号資産取引所のCoinbaseが約8時間にわたり取引停止に陥った。原因はAWS(Amazon Web Services)の米バージニア北部リージョンus-east-1で起きた、1つのアベイラビリティゾーン(AZ、独立した電源・冷却を持つデータセンター群の単位)の冷却故障である[1][3]。Coinbaseは6月2日に詳細なポストモーテム(障害の事後検証報告)を公開した[1]。
クラウド事業者自身の障害発表は抽象的になりがちだが、顧客側のポストモーテムには設計の弱点が具体的に書かれる。今回の報告には、低レイテンシ優先で事実上単一AZに固定されていたマッチングエンジンと、マネージドKafkaサービスのAmazon MSK(Managed Streaming for Apache Kafka)が「落ちずに劣化する」サイレント障害という、業種を問わず通用する2つの教訓が含まれていた。
AZ単位の障害は珍しいイベントではなく、設計上は想定内として扱うべきものだ。本稿では時系列と2つの根本原因を整理し、自社システムが同じ構図を抱えていないかを点検する観点に落とし込む。インフラ運用者だけでなく、可用性投資の意思決定に関わる管理職にも判断材料になるはずだ。
何が起きたか:use1-az4のチラー故障と28時間
5月7日19時20分(米東部時間)、us-east-1のAZ「use1-az4」内の1つのデータホールで複数のチラー(冷却装置)が同時に故障した[1][2]。ラックは熱保護のため自動停止し、AWSは影響範囲のEC2インスタンスを強制終了した。リージョン全体ではなく、1つのAZの一部分で起きた局所障害である。
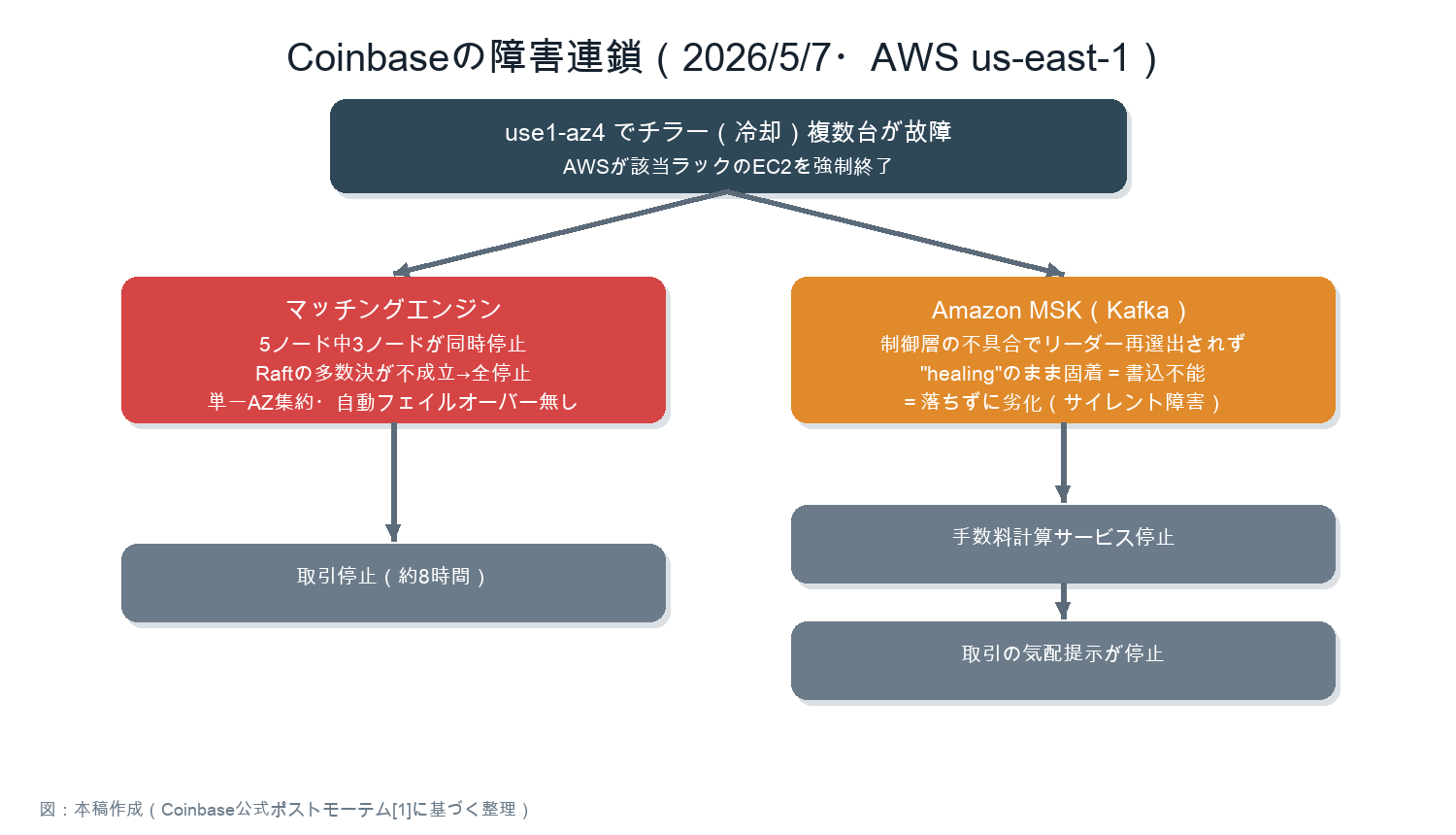
AWS側の影響は解消まで約28時間に及んだ[2]。Coinbaseでは取引・入出金を含む主要機能が約8時間使えず、全システムの完全復旧にはさらに約12時間を要した[1]。
| 時刻(米東部時間) | 出来事 |
|---|---|
| 5/7 19:20 | use1-az4でチラー複数台が故障、ラックが熱保護停止 |
| 5/7 21:29 | AWSがEC2を強制終了。マッチングエンジン5ノード中3ノードを喪失 |
| 5/8 0:06 | 緊急のコード変更と手動構築でクォーラム復旧 |
| 5/8 3:00 | MSKでパーティションの手動再割り当てを開始 |
| 5/8 3:49 | 市場再開 |
| 5/8 14:00 | 全トピックが復旧、完全回復 |
注目すべきは、障害の主役が地震や大規模停電ではなく冷却設備という地味な機械である点だ。単一データホールの熱問題でも、その上に乗る論理構成次第で8時間の全面停止につながる。
低レイテンシ設計の代償:単一AZに固定されたマッチングエンジン
Coinbase Exchangeのマッチングエンジン(売買注文を突き合わせる中核システム)は、Raft(多数決の合意で一貫性を保つアルゴリズム)による5ノードのクラスタ構成だった[1]。注文処理の遅延を最小化するため、EC2のクラスタープレイスメントグループ(インスタンスを物理的に近接配置する設定)に同居させており、事実上単一AZに固定されていた。EC2の強制終了で3ノードが同時停止し、多数決が成立せずクラスタ全体が停止した[1]。
別AZへの自動フェイルオーバーは存在しなかった[1]。復旧には緊急のコード変更と新ノードグループの手動構築が必要で、クォーラム回復までに約2時間半を費やしている。
レイテンシとAZ分散はトレードオフであり、取引所が近接配置を選ぶこと自体は不合理ではない。問題は「単一AZに置く」という判断に、「AZを失ったとき何分で復旧できるか」の検証と訓練が伴っていなかった点にある。意図して受け入れたリスクと、検証されていないリスクは別物だ。
落ちずに劣化する:MSKのサイレント障害
より示唆に富むのはAmazon MSKの挙動である。MSKのコントロールプレーン(クラスタを管理するAWS側の制御層)の不具合により、故障ブローカーからのパーティションリーダー(各データ区画の書き込み担当)の自動再選出が機能しなかった[1]。Coinbaseの2つのMSKクラスタは「healing」状態のまま固着し、プロデューサーは書き込み不能になった。ステータス上は回復中なのに実際には何も進まない、典型的なサイレント障害である。
この影響は連鎖した。Kafkaに依存する手数料計算サービスが止まり、それが取引の気配提示を止めた[1]。最終的にAWSのエンジニアと共同で手動のパーティション再割り当てを行い、優先度の高いトピックは翌朝9時30分、全体は14時に復旧した[1]。
マネージドサービスは構築・運用の手間を委譲できるが、障害時の内部可観測性まで事業者側に委ねることになる。サービスのステータス表示ではなく、「実際に書き込みが成功しているか」をアプリケーション側で常時計測する合成監視がなければ、この種の劣化は検知できない。
教訓を自社に持ち帰る3つの点検項目
第一に、「実質単一AZ」になっている中核コンポーネントの棚卸しである。プレイスメントグループ、AZ固定のサブネット設計、2AZ構成のクラスタなどは、構成図上の冗長性と実際の耐障害性が一致しない代表例だ。Coinbase自身も再発防止策として、2AZ構成だったKafkaクラスタの3AZ化とマッチングエンジンの自動フェイルオーバー整備を挙げている[1]。
第二に、マネージドサービスのエンドツーエンド監視である。書き込み・読み出しを実際に行う合成トランザクションを置き、事業者のステータスと突き合わせる。事業者側コントロールプレーンの不具合は自社では直せないからこそ、検知だけは自前で持つ必要がある。
第三に、コストの意思決定を経営の言葉に翻訳することだ。3AZ化はブローカー台数とAZ間転送費を確実に増やす。一方で今回の構図を放置すれば、失うのは8時間分の売上と顧客の信頼である。可用性投資は「障害が起きたら」ではなく「AZ障害は年単位で必ず起きる」前提で損益を比較すべきだ。
まとめ
Coinbaseのポストモーテムが示したのは、クラウドの冗長性は自動では手に入らないという当たり前の事実である。低レイテンシのための単一AZ集約は意思決定として成立するが、復旧手順の検証とセットでなければ単なる賭けになる。マネージドサービスには、ステータスを信用しない自前の監視を添える必要がある。
まずは自社の構成から「実質単一AZ」の箇所と、ステータス表示しか見ていないマネージドサービスを洗い出すことを勧めたい。AZ障害は想定内のイベントであり、想定内に変える作業は障害が起きる前にしかできない。
出典
[1] Coinbase: A postmortem of our May 7, 2026 outage — https://www.coinbase.com/en-gb/blog/a-postmortem-of-our-may-7-2026-outage[2] AWS Builder Center: The 28-hour meltdown — what happened when AWS us-east-1 overheated — https://builder.aws.com/content/3DTtGltSalD4IteiZ7bEKQ8Tj4E/the-28-hour-meltdown-what-happened-when-aws-us-east-1-overheated
[3] CNBC: AWS data center outage hits trading on FanDuel, Coinbase — https://www.cnbc.com/2026/05/08/aws-outage-data-center-fanduel-coinbase.html








